Phronesis Analytics — www.phronesis-analytics.com
March 2026
We present a unified account of why transformer token embeddings are the primary geometric foundation of attention and what follows from that observation. Starting from the mechanistic interpretability result that grokking on modular arithmetic coincides with Fourier circuit formation in the embedding, we introduce Prescribed Fourier Frequency Training (PFFT), which steers embedding gradients toward near-Nyquist frequency modes and achieves a 92.7% reduction in epochs-to-grokking (57 vs. 782) with a 97.9% reduction in the memorization phase.
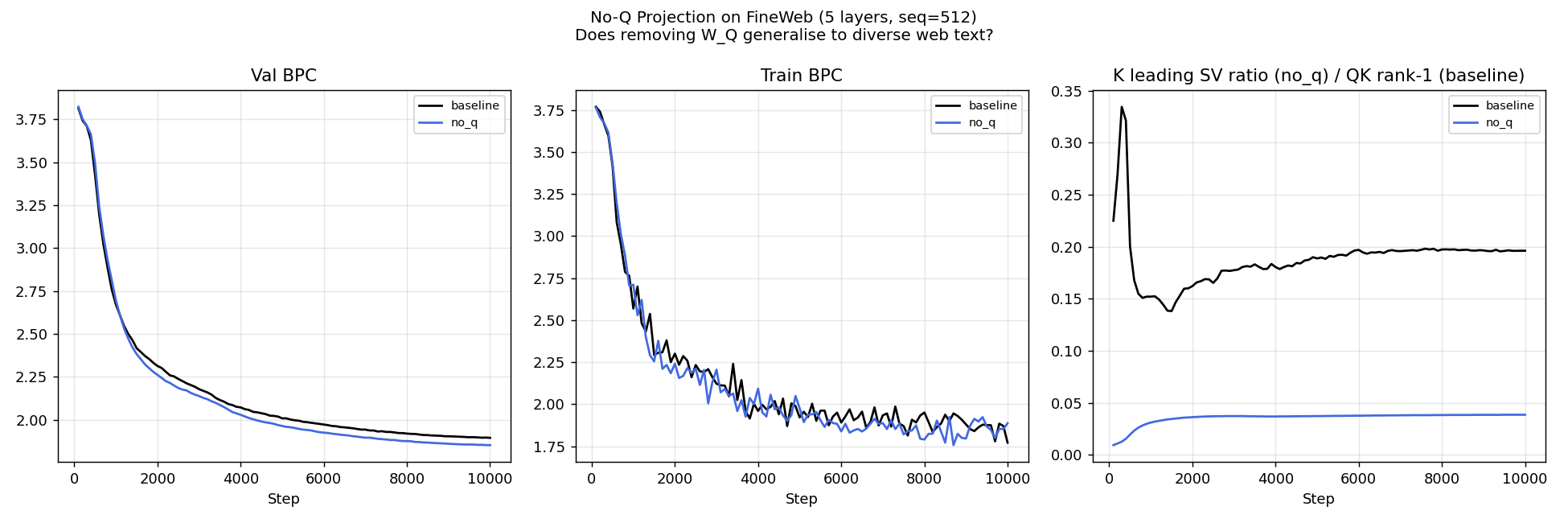
PFFT works because it does two things simultaneously: it respects the embedding's geometric authority and it reduces gradient noise. The Sounding Hammer diagnostic reveals, however, that these gradient-domain techniques do not transfer to language model token embeddings: BPE vocabulary gradients are spectrally flat ($\rho = 0.42$), causing catastrophic BPC regression (2.90→9.47) when Fourier steering is applied. Behavioral weight trajectory analysis of language models trained on TinyStories and FineWeb shows that Q-weight matrices are the primary locus of representational reorganization — sharper and more clustered than K, V, or MLP trajectories. This motivates No-Q attention: setting $\mathbf{Q} = \mathbf{x}$ (no projection) at every layer. No-Q attention achieves the same two goals as PFFT through an architectural change rather than a gradient-domain filter. The result: +3.18% validation BPC on TinyStories and +2.24% on FineWeb with 8% fewer parameters, plus a 58.9% ETG speedup on modular arithmetic. Taken together, these results support the Embedding Geometry Hypothesis: the token embedding is not a lookup table that feeds into attention — it is the attention query, and the Q projection is a redundant reparameterization of a signal the embedding has already encoded.
The transformer computes self-attention via three symmetric projections:
The matrices $\mathbf{W}_Q, \mathbf{W}_K, \mathbf{W}_V \in \mathbb{R}^{d \times d}$ are treated symmetrically in most analyses and architectures. We question this symmetry for $\mathbf{W}_Q$.
The investigation begins with grokking — the phenomenon in which a small transformer trained on modular arithmetic suddenly generalizes after hundreds of epochs of near-perfect training accuracy. The mechanistic interpretability literature has established that generalization coincides with the emergence of a sparse Fourier circuit in the token embedding, not in the attention weights. The attention layers then exploit the geometric structure that the embedding has established.
This suggests a hierarchy: the embedding sets the representational geometry; downstream layers are secondary processors of that geometry. If true, the Q projection — applied to the post-embedding hidden state — is reparameterizing a space the embedding has already structured. It is a redundant degree of freedom that competes with, rather than extends, the embedding's geometric authority.
Research arc. We develop this idea through four stages:
Power et al. (2022) observed that small transformers trained on modular arithmetic $(a+b) \bmod p$ exhibit delayed generalization: training accuracy reaches ~100% hundreds of epochs before validation accuracy does. Nanda et al. (2023) identified the mechanism: generalization coincides with the emergence of a Fourier circuit in the token embedding using modes $\{1, 14, 41\}$ for $p = 97$. The attention weights do not carry this structure independently — they inherit it from the embedding geometry.
This is strong evidence for the Embedding Geometry Hypothesis: the token embedding is the primary carrier of the representational geometry that determines what downstream attention layers can efficiently compute.
We ask: if the embedding is the root, can we accelerate grokking by steering embedding gradients toward Fourier modes that carry more useful structure?
| Method | Prescribed Modes $S$ | ETG | Mem | Speedup |
|---|---|---|---|---|
| Baseline | — | 782 ± 95 | 451 | — |
| PFFT Nanda | $\{1, 14, 41\}$ | 191 ± 5 | 32 | +75.5% |
| PFFT quint | $\{1, 2, 3, 4, 5\}$ | 261 ± 3 | 90 | +66.7% |
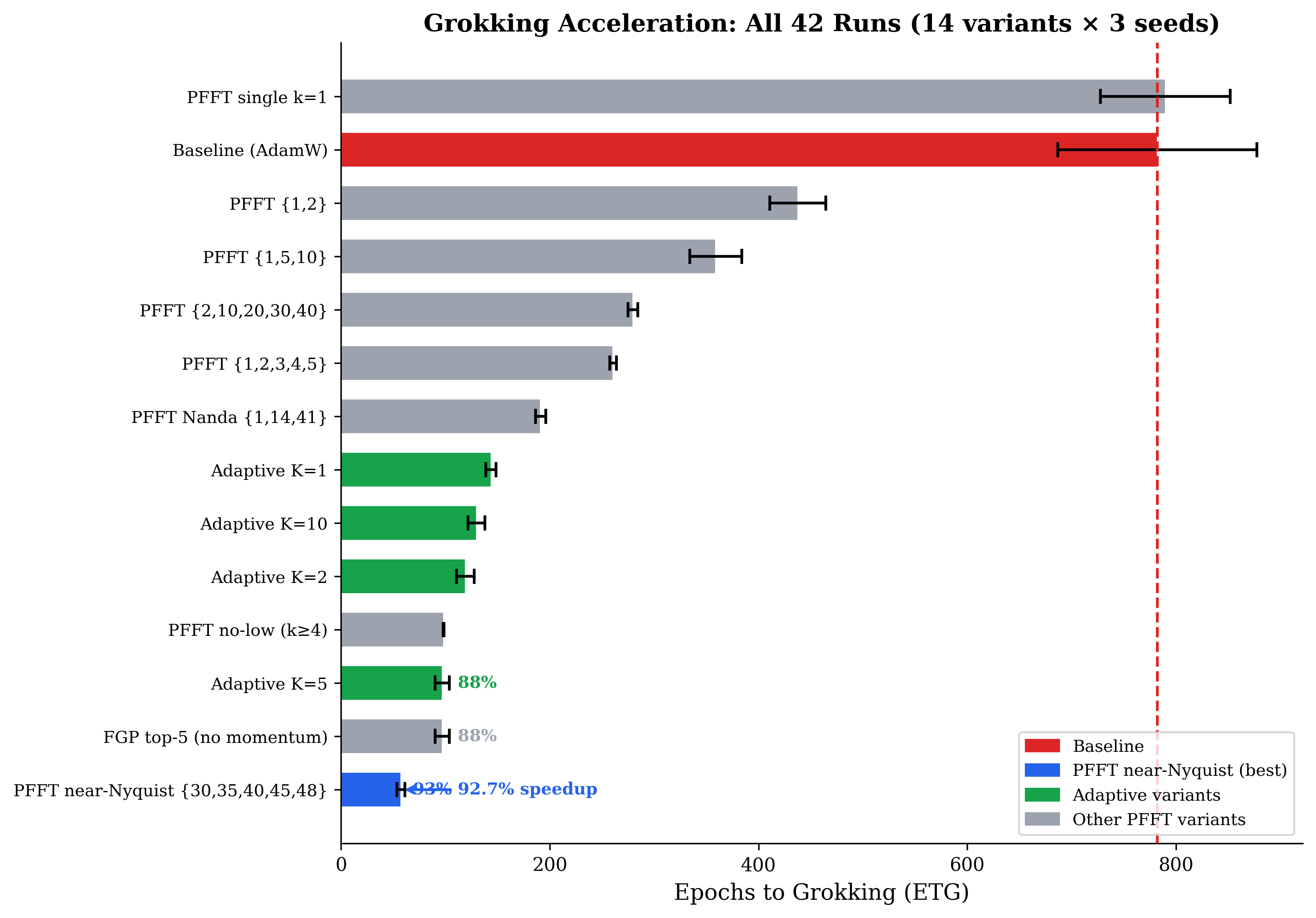
| PFFT near-Nyquist | $\mathbf{\{30, 35, 40, 45, 48\}}$ | 57 ± 4 | 9 | +92.7% |
| Adaptive $K=5$ | top-5 dynamic | 97 ± 7 | 38 | +87.6% |
Near-Nyquist modes $\{30, 35, 40, 45, 48\}$ achieve ETG = 57 (92.7% speedup) and reduce the memorization phase from 451 to 9 epochs (97.9% reduction). Three findings are especially diagnostic:
Near-Nyquist beats task-correct modes. The mechanistic interpretability literature identifies $\{1, 14, 41\}$ as the "correct" modes for $p = 97$. Prescribing these yields 75.5% speedup; near-Nyquist $\{30, 35, 40, 45, 48\}$ yields 92.7%. The speedup comes from gradient noise reduction, not mode guidance. The task-relevant Fourier structure then emerges naturally via the optimization landscape.
Memorization is almost entirely bypassed. Standard training spends 451 epochs memorizing before generalizing. PFFT near-Nyquist grokks at epoch 9 and generalizes at epoch 57: the model generalizes before memorizing in any meaningful sense. Memorization is not a necessary stage — it is a symptom of gradient noise.
| Setup | Prescription | ETG | vs. Baseline |
|---|---|---|---|
| $p=97$, baseline | — | 782 | — |
| $p=97$, near-Nyquist | $\{30,35,40,45,48\}$ | 57 | +92.7% |
| $p=113$, baseline | — | 321 | — |
| $p=113$, near-Nyquist | $\{34,40,46,51,56\}$ | 75 | +76.6% |
| $p=97$, single Nyquist | $\{48\}$ | DNF | — |
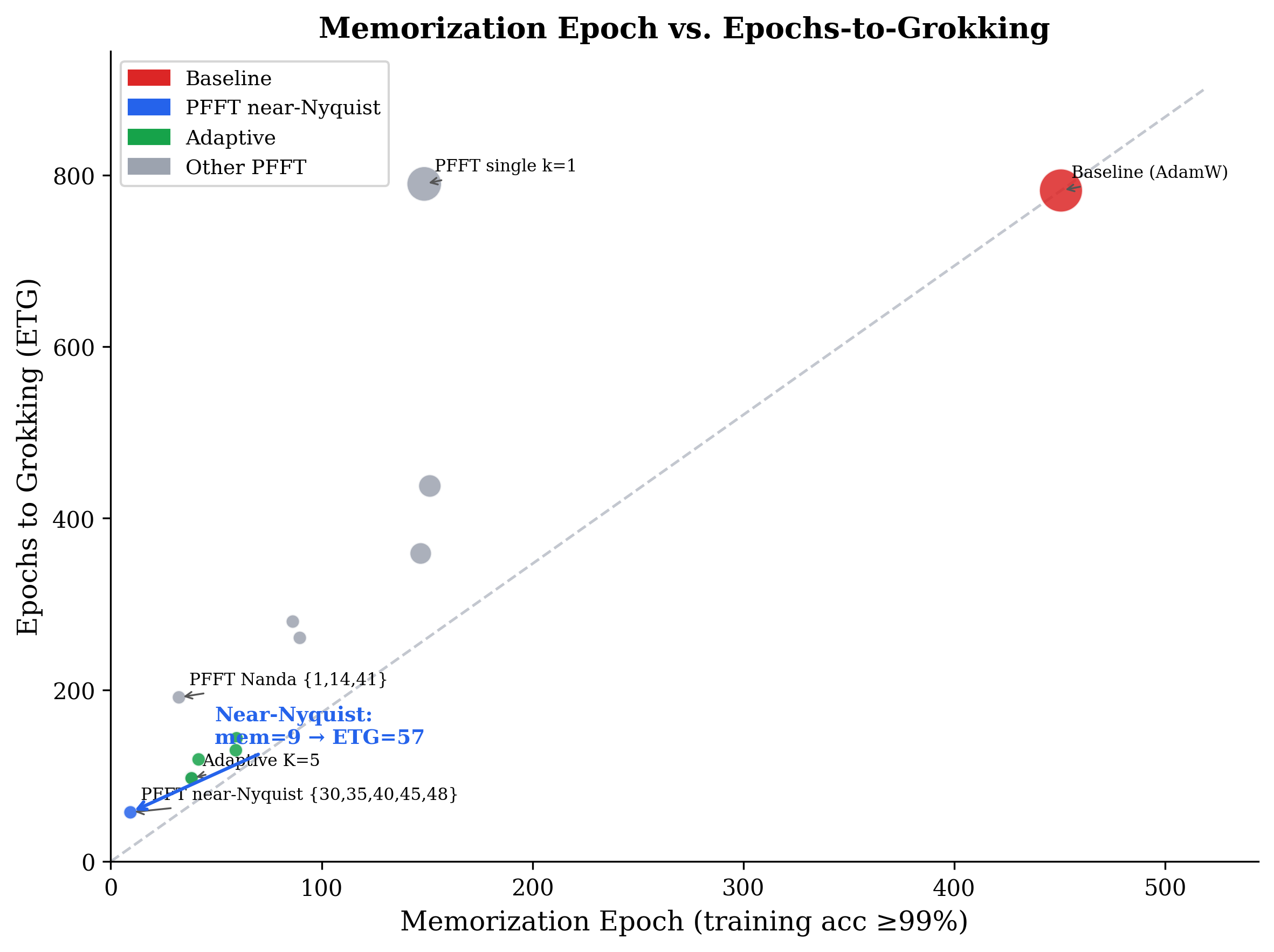
PFFT simultaneously achieves two things:
Both mechanisms are necessary. Prescribing only a single mode (even the Nyquist, $k = 48$) fails to grok entirely: a single mode cannot span the multi-dimensional Fourier circuit required by modular arithmetic, which needs ≥3 independent phase components.
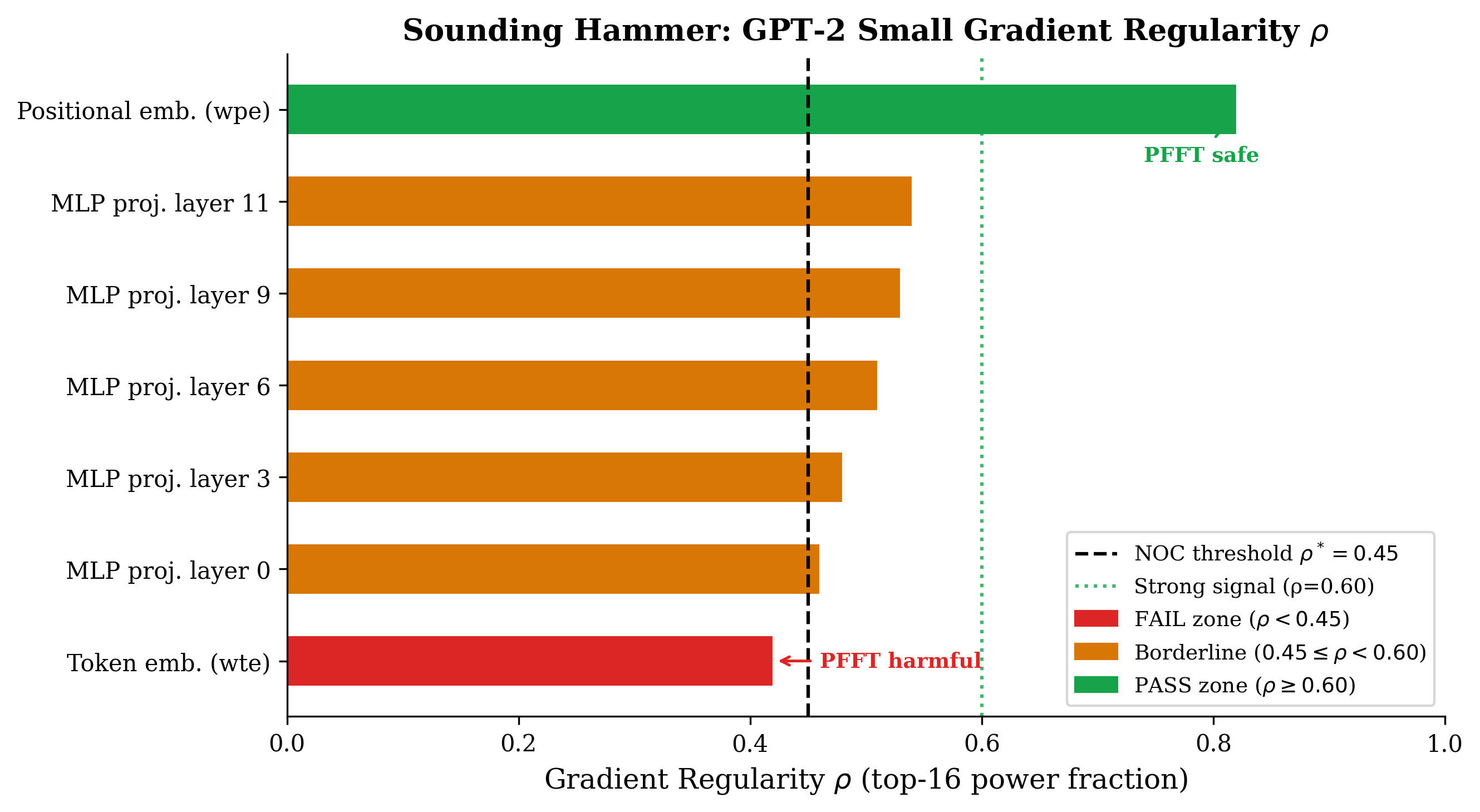
Before applying PFFT to any model, we need to answer two questions: (1) does the gradient along the target parameter axis have structured Fourier content, and (2) if so, which modes dominate? The Sounding Hammer is a pre-training diagnostic that answers both.
The Sounding Hammer returns two outputs:
| Tensor | Description | $\rho$ |
|---|---|---|
wpe.weight |
Positional embedding (512×768) | 0.82 (PASS) |
h.*.mlp.c_proj.weight |
MLP output projections (avg 12 layers) | 0.45–0.54 |
wte.weight |
BPE token embedding (50,257×768) | 0.42 (FAIL) |
Applying PFFT near-Nyquist to BPE vocabulary gradients causes BPC to increase from 2.90 to 9.47 — a catastrophic regression. Projecting onto 5 of 25,128 bins discards nearly all informative gradient signal. The degradation is not specific to mode choice; it reflects the NOC violation.
| Variant | Description | BPC at 10k steps |
|---|---|---|
| Baseline | No FGP | 2.90 |
| PFFT near-Nyquist | $\{25124, \ldots, 25128\}$ | 9.47 (catastrophic) |
| Adaptive FGP $K=5$ | Top-5 gradient modes | ~4.0 (degraded) |
This leaves a key question: gradient-domain noise reduction works beautifully for modular arithmetic, and the embedding is clearly the geometric root in both settings. But the noise reduction mechanism cannot be applied the same way. What is the right intervention for language models?
To understand which components of the transformer undergo the most significant representational change during training, we collect per-step weight snapshots of the Q, K, V, and MLP weight matrices across all layers for language models trained on TinyStories and FineWeb.
Each snapshot is encoded by a behavioral autoencoder (dual-objective: weight reconstruction loss + training-loss prediction from the bottleneck) and projected to 2D via PyMDE. HDBSCAN clustering reveals the number and structure of distinct behavioral phases.

The pattern is consistent across all layers and replicated on the FineWeb model:
The Q weights are doing something the K and V weights are not: they are repeatedly reorganizing to match a shifting query geometry. But the query geometry is exactly what the embedding encodes. Under the Embedding Geometry Hypothesis, the Q projection is competing with the embedding for representational ownership of the query space, and the sharpness of the Q trajectory reflects the cost of that competition.
This analysis points directly at a hypothesis: if we remove the Q projection, the embedding can set the query geometry without competition, and the representational reorganization cost disappears.
No-Q attention replaces standard self-attention (Eq. 1) with:
The post-LayerNorm hidden state $\mathbf{x}$ serves directly as the query. $\mathbf{W}_Q$ is removed entirely; $\mathbf{W}_K$, $\mathbf{W}_V$, and $\mathbf{W}_O$ are retained without modification.
Goal 1: Embedding geometry authority. When $\mathbf{Q} = \mathbf{x}$, the query is the hidden state as shaped by the embedding and all preceding layers. There is no learned projection competing to reshape the query geometry. The embedding's representational choices propagate directly into the query-key dot product. This is the architectural equivalent of PFFT's gradient-domain intervention: instead of filtering gradients to keep the embedding's structure intact, we remove the parameter that would otherwise overwrite it.
Goal 2: Gradient noise reduction. Removing $\mathbf{W}_Q$ eliminates $L \times d^2$ parameters. For our 4-layer, $d = 256$ model: $4 \times 65{,}536 \approx 262$K parameters (8% of total). Fewer parameters means a smaller-dimensional optimization landscape with lower inherent noise. Unlike PFFT, this noise reduction requires no knowledge of the gradient's spectral structure and is always safe to apply.
Why K and V are kept. $\mathbf{W}_K$ is necessary because K must be in a space compatible with the dot product against $\mathbf{x}$: without $\mathbf{W}_K$, the attention pattern collapses to a function of pairwise $\|\mathbf{x}\|$ only. $\mathbf{W}_V$ is necessary to select what information flows forward — a distinct operation from the query-key relevance computation.
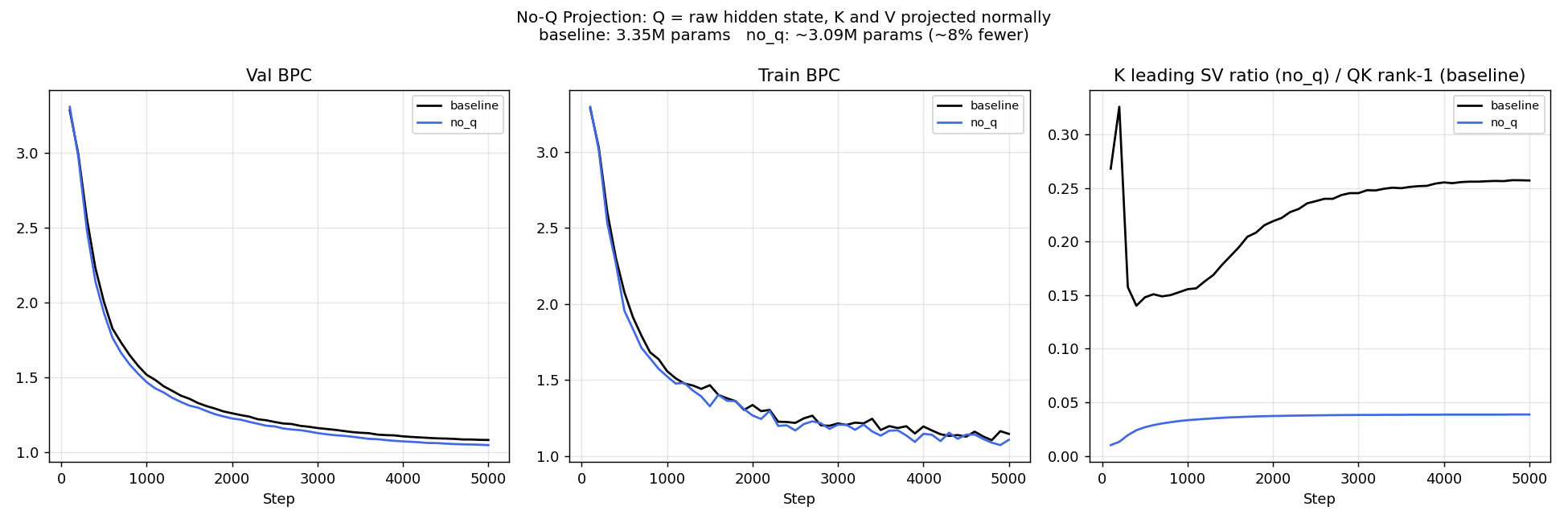
All language model experiments use a byte-level character language model with $d = 256$, $L = 4$ layers, $H = 4$ heads, $d_\text{MLP} = 1024$, sequence length 256, vocabulary size 256. Total parameter count: 3.35M (baseline) / 3.09M (No-Q, −8%). Trained with AdamW, LR $= 3 \times 10^{-4}$, weight decay $= 0.1$, cosine schedule, batch size 64, 5000 steps.
Datasets:
| Variant | Params | Val BPC | Δ BPC | Δ% |
|---|---|---|---|---|
| Baseline (standard) | 3.347M | 1.0819 | — | — |
| No-Q attention | 3.085M | 1.0475 | $-0.0344$ | +3.18% |
No-Q attention improves validation BPC from 1.0819 to 1.0475 — a 3.18% relative improvement — with 8% fewer parameters. The improvement appears early in training and persists throughout. This is the largest improvement of any architectural modification tested, achieved by removing computation rather than adding it.
| Variant | Params | Val BPC | Δ BPC | Δ% |
|---|---|---|---|---|
| Baseline (standard) | 4.200M | 1.8942 | — | — |
| No-Q attention | 3.872M | 1.8518 | $-0.0424$ | +2.24% |
No-Q attention generalizes from TinyStories to the more challenging and diverse FineWeb corpus. The 5-layer model achieves a 2.24% BPC improvement while removing 7.8% of parameters. The consistency of the result across both datasets is important: FineWeb spans news, blogs, science, and code — a much richer distribution than children's stories. The improvement is not an artifact of distributional simplicity.
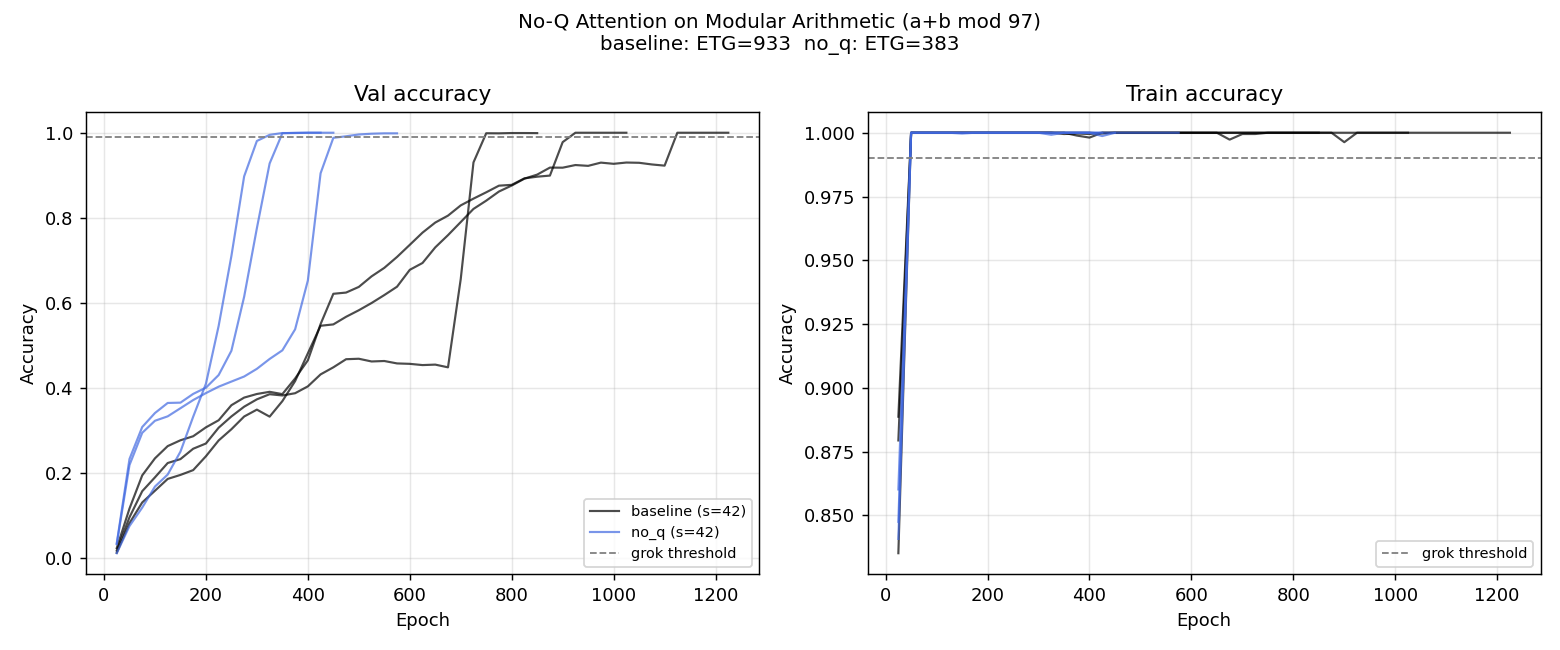
We test whether No-Q attention changes grokking dynamics on modular arithmetic. Setup: $(a+b)\bmod 97$, $d = 128$, $L = 2$, $H = 4$, 40% train split, AdamW LR $= 10^{-3}$, WD $= 1.0$, up to 1500 epochs, 3 seeds.
| Variant | ETG (mean) | ETG (seeds) | Mem. eps | Speedup |
|---|---|---|---|---|
| Baseline | 933 | 925, 1125, 750 | 50 | — |
| No-Q attention | 383 | 325, 350, 475 | 50 | +58.9% |
| PFFT near-Nyquist (ref.) | 57 | — | 9 | +92.7% |
No-Q attention reduces mean ETG from 933 to 383 epochs — a 58.9% speedup. The memorization epoch (mem-eps = 50) is identical for both variants. No-Q does not accelerate memorization; it shortens the gap between memorization and generalization. The standard model spends 883 epochs after memorization before generalizing; No-Q spends only 333. Under the Embedding Geometry Hypothesis, removing $\mathbf{W}_Q$ eliminates the competition for representational ownership of the query space, allowing the embedding's Fourier structure to be directly exploited once memorization is complete.
The results across all four stages of the investigation tell a coherent story:
The standard transformer treats $\mathbf{W}_Q$ and $\mathbf{W}_K$ symmetrically, but there is a fundamental asymmetry in their roles. $\mathbf{W}_K$ produces the key space: it defines "what to compare against" for each position — a genuinely helpful degree of freedom. Without $\mathbf{W}_K$, the attention pattern collapses to pure self-similarity.
$\mathbf{W}_Q$ produces the query space: it defines "what this token is looking for." But this information is already encoded in the embedding geometry. What a token wants is precisely what the embedding encodes. $\mathbf{W}_Q$ reparameterizes a signal that was already present.
Grokking and Fourier circuits. Power et al. (2022) introduced grokking. Nanda et al. (2023) showed generalization coincides with Fourier circuit formation in the token embedding. GrokFast amplifies slow-gradient components but requires the memorization phase first; PFFT sidesteps memorization entirely.
Attention simplifications. Multi-query attention (MQA) and grouped-query attention (GQA) share K and V heads across Q heads to reduce KV-cache memory. Linformer and linear attention modify the attention kernel. None of these is equivalent to No-Q attention, which removes the Q projection matrix entirely.
Spectral bias and gradient dynamics. Rahaman et al. (2019) established that gradient descent is biased toward low-frequency solutions. This bias is harmful for modular arithmetic, where the optimal solution requires high-frequency representations near the Nyquist limit.
Embedding structure. Our work argues that the embedding's geometric independence must be preserved, not post-processed, and that the Q projection is the primary threat to that independence.
We have presented the Embedding Geometry Hypothesis and traced its implications from modular arithmetic to language modeling.
Starting from Fourier circuit formation in grokking, we showed that prescribing near-Nyquist embedding gradients (PFFT) achieves 92.7% ETG speedup by simultaneously respecting the embedding's geometric authority and reducing gradient noise. The Sounding Hammer revealed that the same gradient-domain technique cannot be applied safely to language model token embeddings. Behavioral weight trajectory analysis identified the Q projection as the primary site of representational reorganization, pointing directly at the intervention: remove $\mathbf{W}_Q$.
No-Q attention — setting $\mathbf{Q} = \mathbf{x}$ at every layer — improves language modeling BPC by +3.18% on TinyStories and +2.24% on FineWeb while removing 8% of parameters, and accelerates grokking by 58.9% on modular arithmetic.